|
I am a Machine Learning Engineer at Adobe, working on generative video within the Adobe Firefly team. I believe AI is the best tool humanity has ever built, and that using it to solve hard problems in medicine, especially diseases like cancer, is the most noble use we can find for it. As a researcher, I am drawn most to representation learning for complex biomedical data, where AI can help extract structure that scientists and clinicians can actually interpret and act on. I completed my M.S. in Computer Science (AI) at UC San Diego; my master's thesis, 4D MitoSpace: A Self-Supervised Deep Learning Framework for Spatio-Temporal Mitochondrial Phenotyping, was advised by Johannes Schöneberg at UC San Diego Health. The work develops self-supervised representation learning for 4D single-cell microscopy to capture mitochondrial phenotypic responses to drug perturbations and support biological interpretation for drug discovery. I earned my B.Tech. in Information Technology from IIIT Allahabad. During my M.S., I was a Machine Learning Research Intern with the Adobe Firefly team [project page]. Earlier, I was a Deep Learning Researcher at Rephrase.ai (later acquired by Adobe) and an engineer at Udaan on warehouse robotics. Email / GitHub / Google Scholar / LinkedIn / Unsplash |

|
|
My research is on applying AI to challenging problems in medical science and healthcare, with a focus on representation learning for the complex, high-dimensional data that arises in biomedical settings, such as 4D single-cell microscopy, fluorescence imaging, and other modalities relevant to drug discovery and clinical reasoning. The goal I care about is learning structure that scientists and clinicians can interpret and act on, not just optimizing benchmark numbers. More broadly, I have a long-standing interest in mathematics and physics. I find both fields beautiful in their own right, and they continue to shape how I think about modeling, structure, and reasoning in AI. |
|
|
|
Master's Thesis · UC San Diego Health Advisor: Johannes Schöneberg Thesis (ProQuest) → A self-supervised representation-learning framework for 4D single-cell microscopy (x, y, z, t), producing embeddings that capture mitochondrial phenotypic responses to drug perturbations for drug discovery. The associated manuscript is currently under peer review at Cell, and both the thesis and the project site at mitospace.ai are embargoed during this period. |
|
|
Edge
Depth
Generated
|
Adobe Firefly · Research Internship, Summer 2024 Mentors: Gunjan Aggarwal, Lakshya, Kshitij Garg Project page → A modular adapter that augments a DiT-based text-to-video backbone with edge and depth structural conditioning. A single checkpoint supports dense, sparse, and single-frame temporal control, with continuously adjustable per-modality strength at inference. |
|
|

|
|
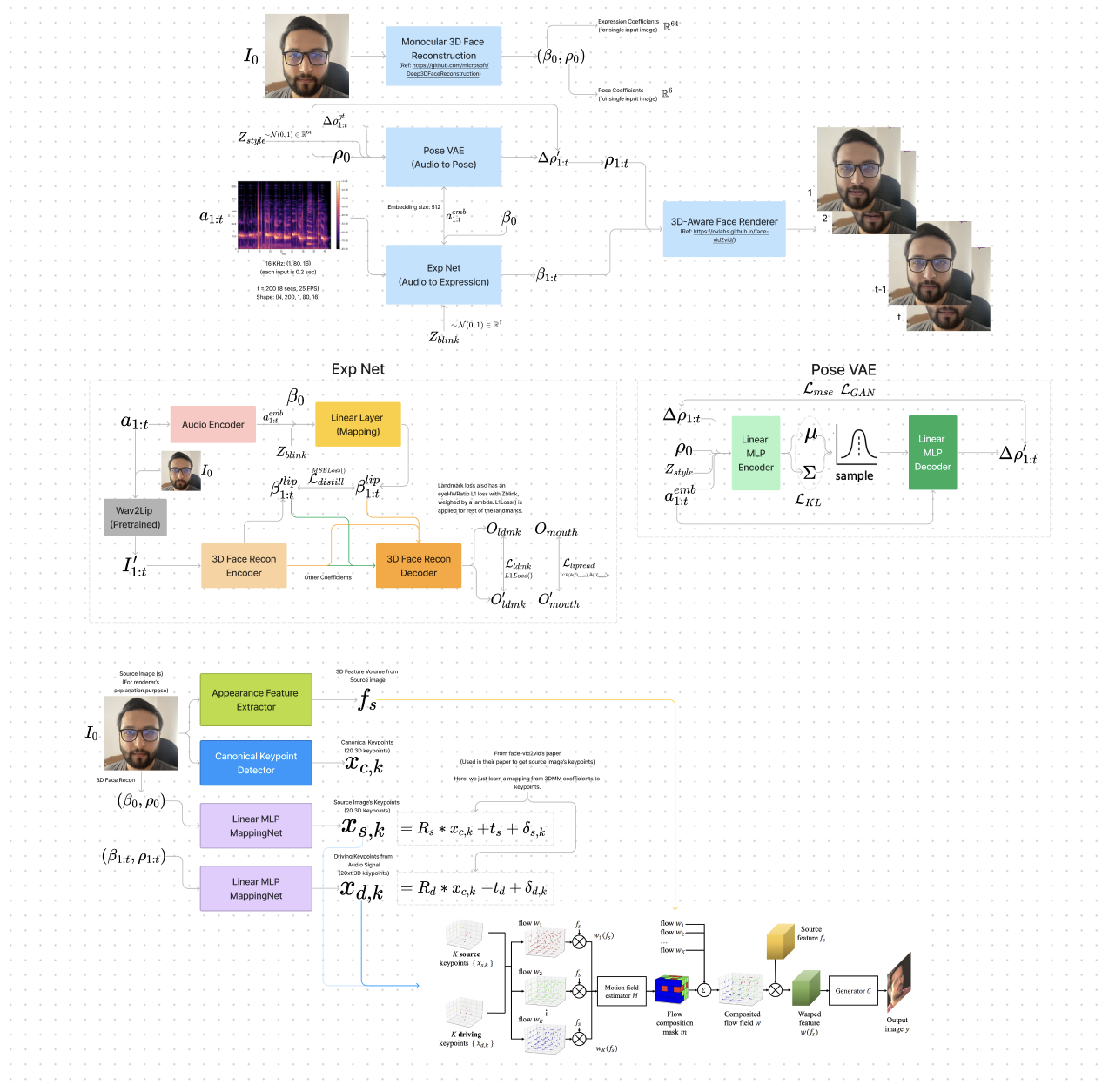
An internal pipeline for synthesizing talking-head video from one portrait image and a speech track. Audio drives an expression network that predicts per-frame 3D morphable model (3DMM) coefficients; those coefficients and the source image feed a neural face renderer. Frames are composed into a temporally coherent clip aligned to the input audio. Hover over the thumbnail to preview a sample result. |
|
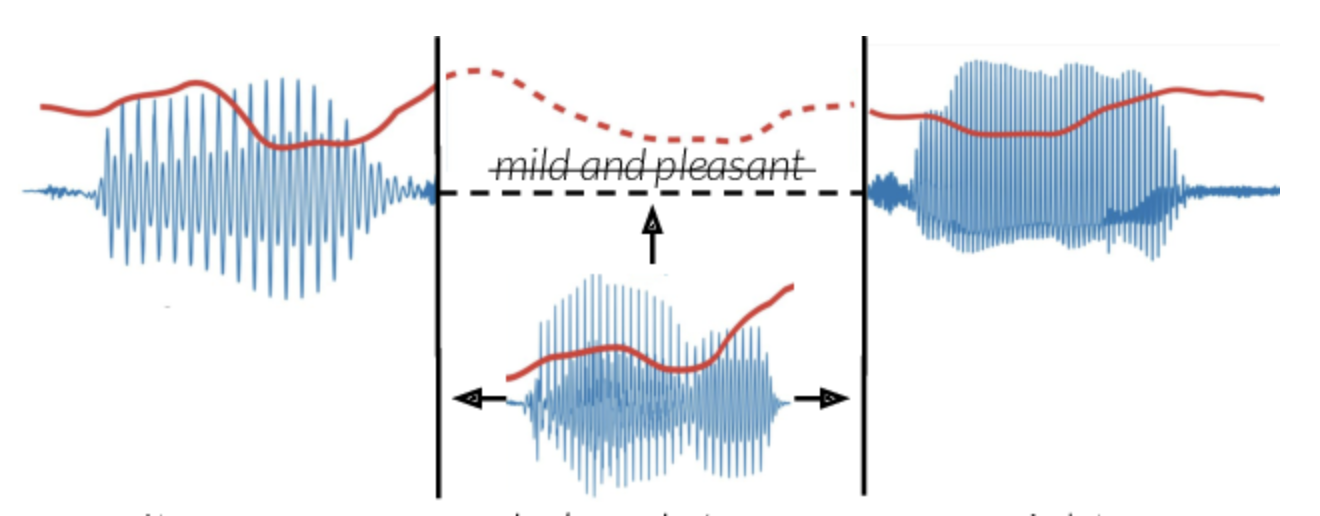
Goal: transfer the prosody of a full spoken sentence onto an isolated target word while preserving lexical content. Inputs are (i) a short word clip from a resynthesized or TTS voice and (ii) a reference sentence from the target speaker. A two-stage model first maps the word’s mel spectrogram with a CNN so that prosody matches the sentence while content stays fixed; a Wasserstein GAN then refines the mel before vocoding to waveform. The result is seamless audio with corrected stress and timing relative to the reference. |

|

|
Autonomous forklift prototype for navigation and pick/place in a warehouse. Front-mounted stereo cameras and additional sensors support localization; strategically placed AprilTags provide robust pose cues and define control points for Bézier-curve trajectories. Hover over the thumbnail to see a simulation of a planned path. |
|
|

|
Tanay Agrawal, Dhruv Agarwal, Michal Balazia, Neelabh Sinha, Francois Bremond International Conference on Computer Vision Theory and Applications (VISAPP), 2022 arXiv Personality recognition from audio, visual, and behavioral cues using cross-attention Transformers and hand-crafted behavior encodings. |
|
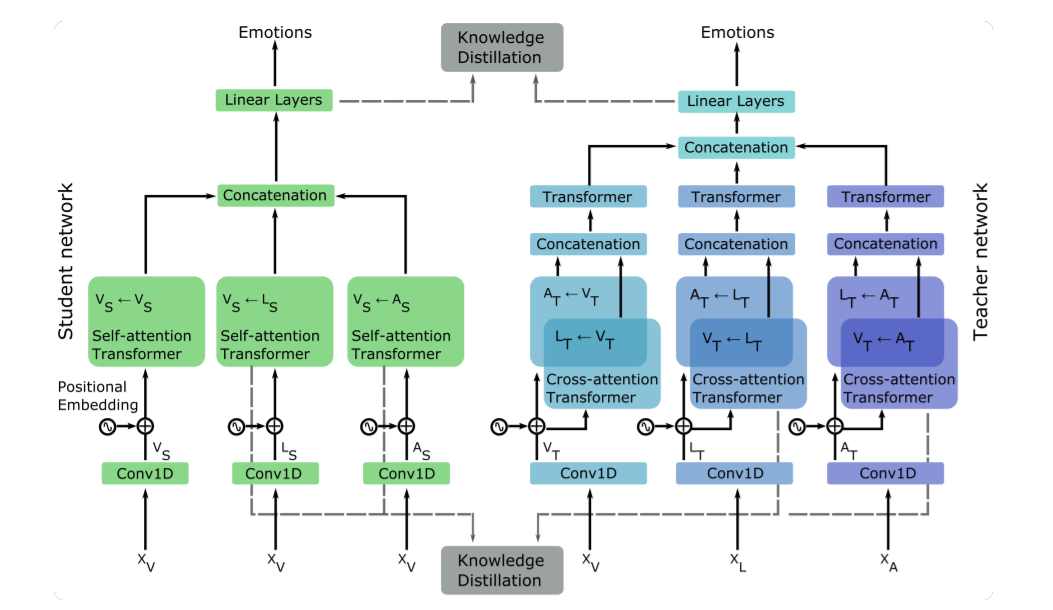
Dhruv Agarwal, Tanay Agrawal, Laura M Ferrari, Francois Bremond Advanced Video and Signal-based Surveillance (AVSS), 2021 arXiv · Slides Distills a multimodal Transformer into a unimodal student via attention-level supervision, reducing modality dependence at inference. |
|
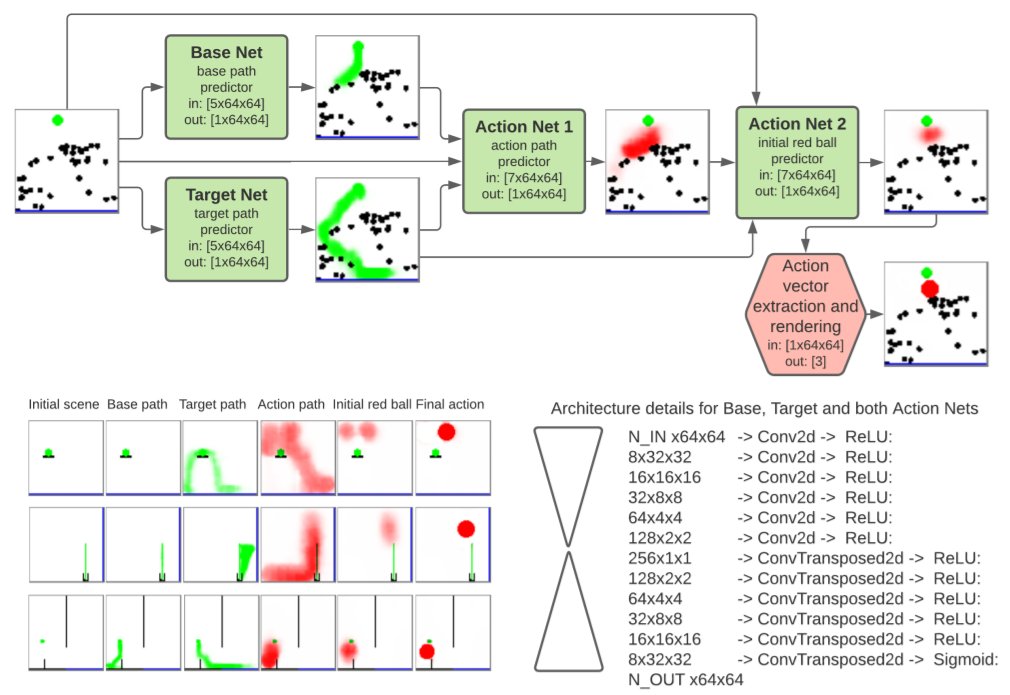
Augustin Harter, Andrew Melnik, Gaurav Kumar, Dhruv Agarwal, Animesh Garg, Helge Ritter NeurIPS workshop on Interpretable Inductive Biases and Physically Structured Learning, 2020 arXiv · Video · Code Neural model for PHYRE-style physics puzzles: plan interventions by reasoning about object trajectories and stable paths to goals. |
|
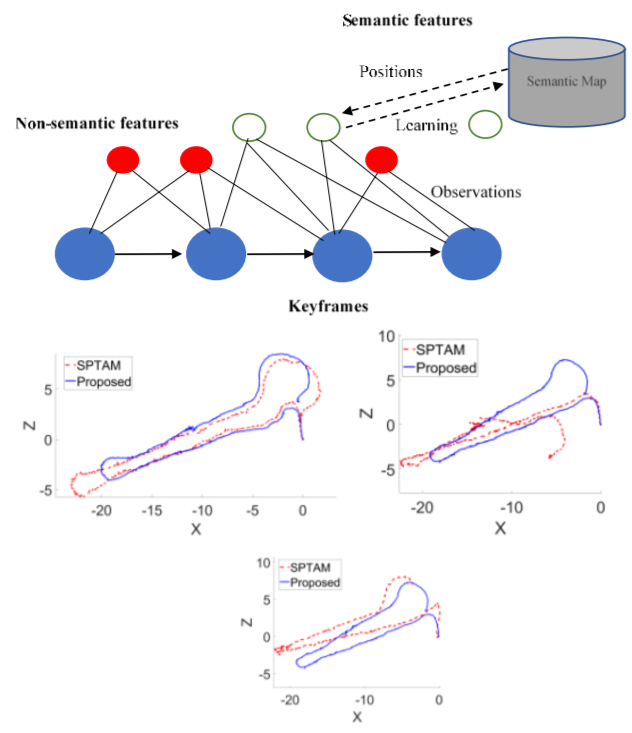
Ambuj Agrawal, Dhruv Agarwal, Mehul Arora, Ritik Mahajan, Shivansh Beohar, Lhilo Kenye, Rahul Kala (equal contribution) Mediterranean Conference on Control and Automation, 2022 Paper V-SLAM with richer semantics: corner-like features and detected objects support place recognition and correspondence, improving localization and loop closure on a mobile robot. |
|
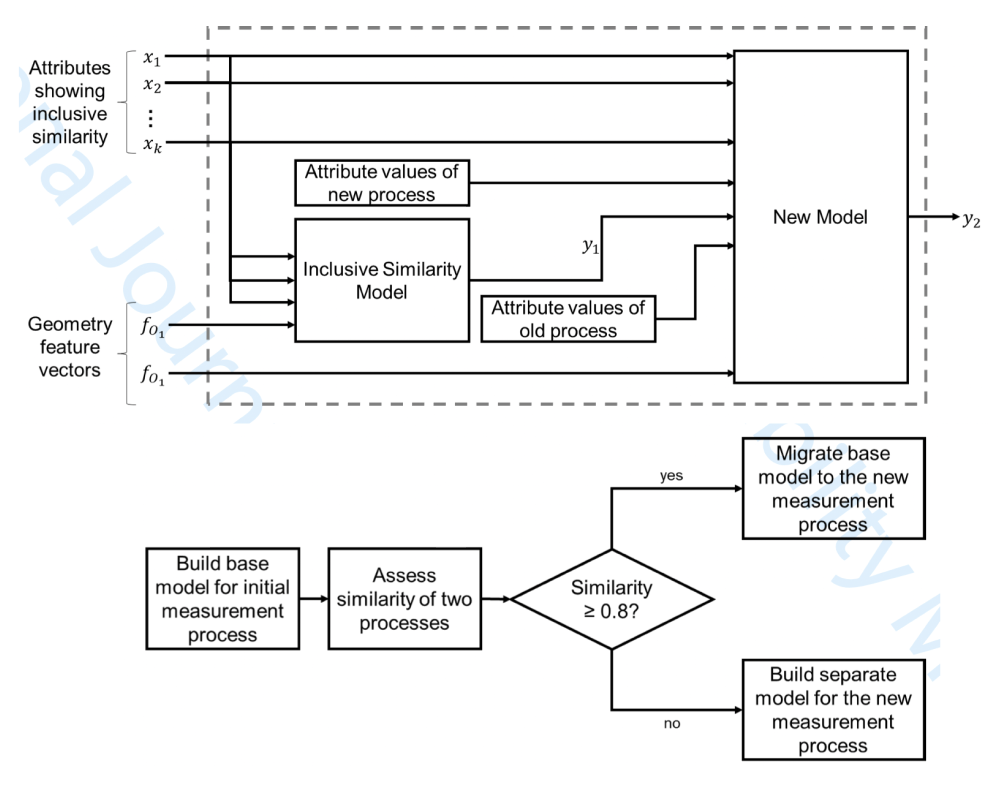
Dhruv Agarwal, Meike Huber, Robert Schmitt. International Journal of Quality & Reliability Management (IJQRM), 2022 Paper Framework for deciding when an existing uncertainty model can be migrated to a related measurement process, reducing repeated metrology modeling effort while guarding against invalid reuse (IJQRM). |
|
|

|
Dhruv Agarwal, Mehul Arora, Gillian McMahon, Jillian Sweetland, Shivansh Tiwari, Shriya Shetty. [Hackathon Presentation] First place, new-venture track, Soonami Venturethon (2023). AutoChart turns clinician–patient dialogue into structured chart notes so providers can focus on care rather than documentation. |
|
|
Dhruv Agarwal, Apoorv Agnihotri, Amit. [Code] First place, generative-AI track, internal hackathon at Rephrase.ai. ChatComix generates interactive comics from high-level controls (genre, length, tone), combining LLM planning with a comic-style presentation layer. |
|
|

|
Unofficial reimplementation of Phase Transitions, Distance Functions, and Implicit Neural Representations, including phase loss for sharper INR fits and an optional Fourier feature layer for high-frequency detail. |
|
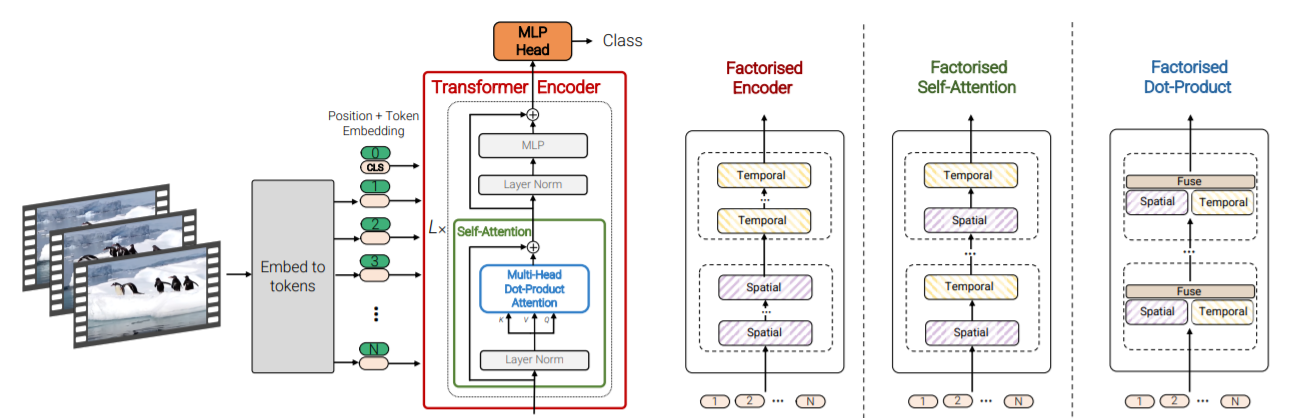
Unofficial PyTorch implementation of the Video Vision Transformer (ViViT) for video classification and spatiotemporal feature extraction. |
|
Classic RL algorithms (DQN, A3C, PPO, and related baselines) applied to Atari-style and FPS environments (e.g., Doom, Space Invaders, Sonic the Hedgehog 2). |

|
DCGAN variants trained on CelebA for photorealistic synthetic faces. |
|
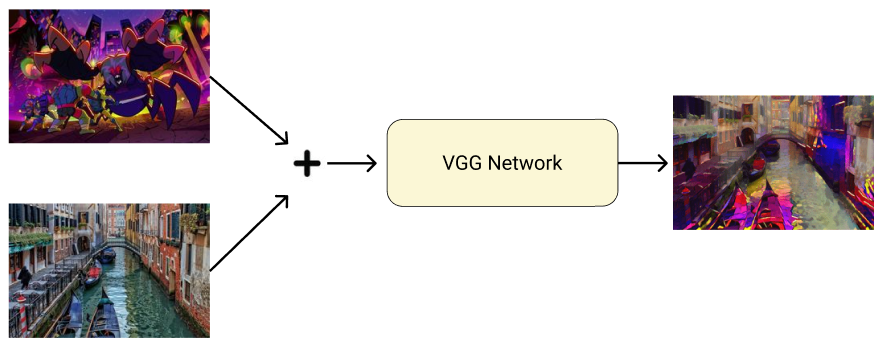
Neural style transfer with a VGG backbone: combine a content image and a reference style to produce stylized outputs. |
|
Occasional writing on ML practice and hackathons. Getting prepped with machine-learning skills for a hackathon (dev.to). |

|
|
Design and source code from Jon Barron's website |